AWS Cloud Project Bootcamp - IaC

Backend-focused full-stack developer with AWS cloud knowledge. AWS Community Builder (Serverless category). Passionate about knowledge sharing.
After spending months working through the bootcamp and creating resources through 'click ops' and AWS CLI, it was time to start automating our infrastructure provisioning. For most of the stacks we used CloudFormation, however, the DynamoDB stack was created by using AWS SAM (Serverless Application Model). During week 8 we had also already created the Serverless Image Processing by using AWS CDK (Cloud Development Kit).
Before deciding the design of your stacks it's important to consider how they are all connected. Which stack needs to be created first and which stacks are going to reference each other? Our stacks and the way they cross-reference each other are shown in the diagram and described in more detail below.
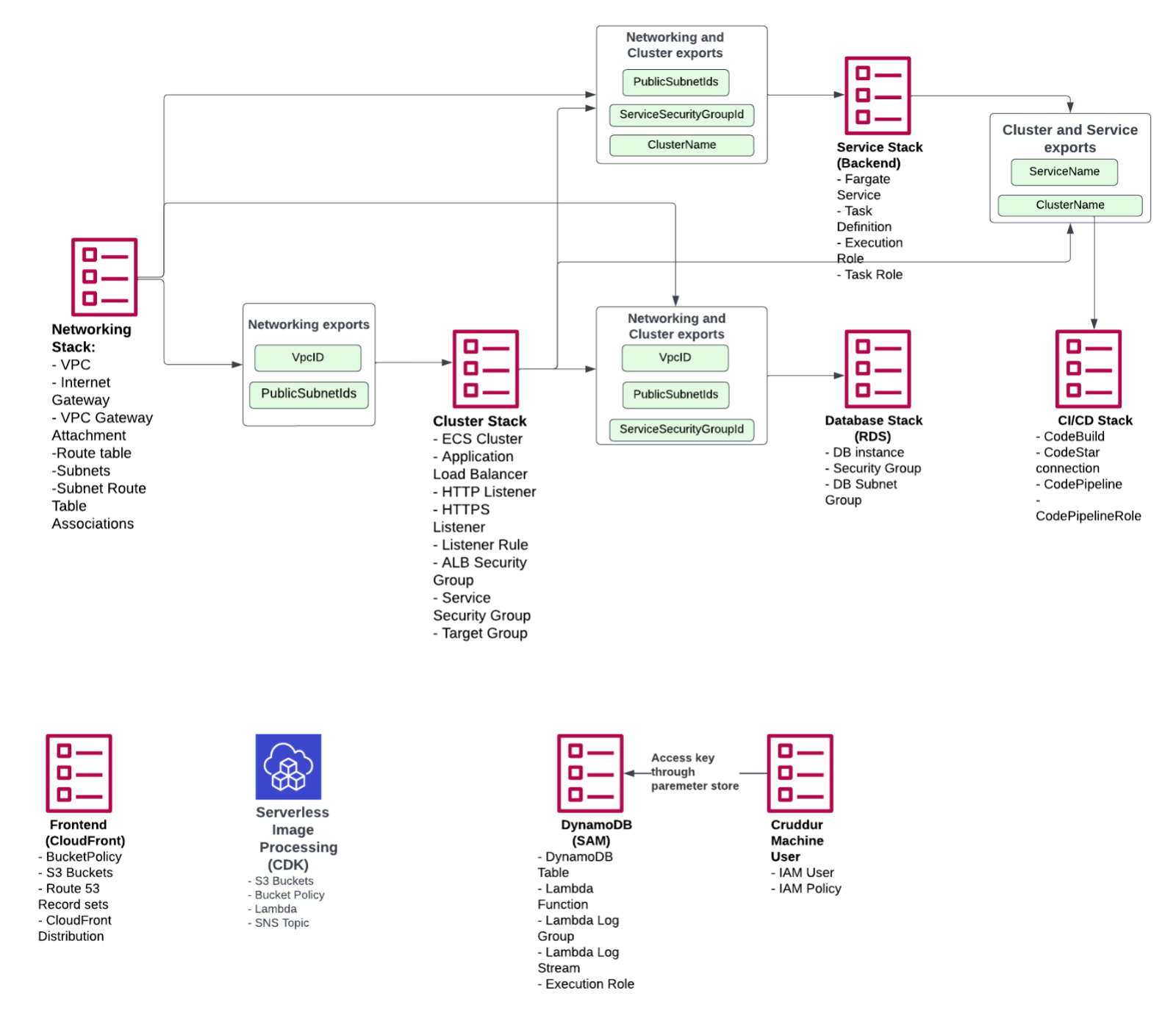
Networking, Cluster, Service and Database Layers
All of the CloudFormation artifacts are going to be stored in an S3 bucket that was created manually through the AWS console before we started creating the individual CloudFormation templates.
The first stack was created for the 'networking layer'. We had previously used the default VPC during the bootcamp, but at this point, it was decided that we want to create a custom VPC. Apart from VPC, the networking stack creates also an internet gateway, VPC gateway attachment, route tables, subnets (3 public subnets and 3 private subnets that are not yet used) and subnet route table associations. Any values that other stacks might need are exported so that those can be referenced by other stacks.
The second stack to be created was for the 'cluster layer'. It contains the ECS cluster, application load balancer, HTTP&HTTPS listeners, listener rules, ALB security group, service security group and target group. To the HTTPS listener we imported the CertificateArn we had already created during one of the previous weeks.
The 'service layer' is one where you have to carefully consider which services you want to include within one template. You might not want to have something like ECR or task definitions tightly coupled in a CloudFormation template. We ended up including task definition in the template, however later realized this was not the best possible approach as now updating our task definition causes our Fargate service to restart as well, and that is something that we would like to handle only through the CI/CD pipeline.
The 'database layer' includes an RDS database instance, security group and database subnet group. The database layer ends up being quite tightly coupled with the service layer as the service layer keeps hanging and re-starting containers without a successful db connection. For this reason, we had to move the service security group from the service stack to the cluster stack, so that it is created first.
The above-mentioned stacks are connected as they reference each other as shown in the diagram. The stacks that are introduced next are different as they are independent and don't cross-reference other stacks.
Frontend (CloudFront)
The React.js frontend of this application was originally built as a container. We containerized the application on week 1 and deployed it as a service to Fargate on week 6. However, throughout the bootcamp there was a discussion about whether the frontend should be deployed using S3 and CloudFront instead. The benefits of using ECS would be on-demand-based scaling, easier version control and rollbacks and advanced deployment options such as canary deployments.
For purposes of this bootcamp it was decided that utilizing S3 and CloudFront is sufficient and makes more sense than deploying it as a container. We proceeded by implementing this directly via CloudFormation rather than creating it manually first like we have done with other stacks.
The frontend stack creates a CloudFront distribution, S3 bucket, bucket policy and Route 53 record set. Deploying any changes happens now by manually creating a static build and then using a library called `aws_s3_website_sync`, which syncs a folder from the local dev environment to the S3 bucket and then invalidates the CloudFront cache. A CI/CD pipeline could be created for this by using GitHub Actions.
DynamoDB Layer (SAM)
The DynamoDB layer was created using AWS SAM, which is a subset of CloudFormation. It is designed especially for serverless applications and provides a simplified and higher-level abstraction for defining and deploying serverless resources. The stack created a DynamoDB table, Lambda function, Lambda log group, Lambda log stream an execution role.
As it's not a security best practice to use our main user's access key to update our DDB table, a new CloudFormation stack for 'machine user' was created. This IAM user has access to update DynamoDB. The access keys were manually updated to the parameter store.
Serverless Image Processing (CDK)
The serverless image processing was created by using AWS CDK (Cloud Development Kit). With CDK you can use your preferred programming language (in this case TypeScript) to define your AWS resources. CDK automatically generates CloudFormation templates based on the infrastructure code you write.
The CDK stack creates two S3 buckets, bucket policy, Lambda function and SNS topic. It is worth noting that the whole serverless image processing architecture required two further Lambda functions and a CloudFront distribution. These were created manually through the AWS console and haven't yet been managed by any IaC tool.
Final Thoughts
In conclusion, our journey to automate infrastructure provisioning has achieved significant milestones. What still remains, is incorporating the serverless image processing fully into CloudFormation by leveraging the CDK stack as a nested stack and ensuring all necessary Lambda functions are included in the CloudFormation template. Additionally, the frontend could be fully automated by implementing a CI/CD pipeline, such as GitHub Actions.
Link to my previous article about AWS Cloud Project Bootcamp's DynamoDB week.