

Boost Data Modeling Efficiency Using Amazon DynamoDB MCP Server
M
Backend-focused full-stack developer with AWS cloud knowledge. AWS Community Builder (Serverless category). Passionate about knowledge sharing.
Search for a command to run...
Backend-focused full-stack developer with AWS cloud knowledge. AWS Community Builder (Serverless category). Passionate about knowledge sharing.
No comments yet. Be the first to comment.
It is interesting to think how our understanding of a topic is influenced by our earlier, seemingly completely unrelated experiences. I didn't initially learn systems thinking from cloud architecture,
When I started building an application that extracts key concepts and vocabulary from a text, I thought I could handle personalisation through the prompt alone. It turned out that getting reliable res
As a backend-focused developer whose preference is not to fiddle with UI elements, manually writing tests for UI quirks is a chore I’d rather avoid. An AI-powered testing framework built on Playwright

The new AI IDE, Kiro, has just been launched in preview, and over the past few weeks, I have been able to try its features. Below, I share some of my initial experiences and the unique advantages Kiro has brought to my software development flow. Ki...

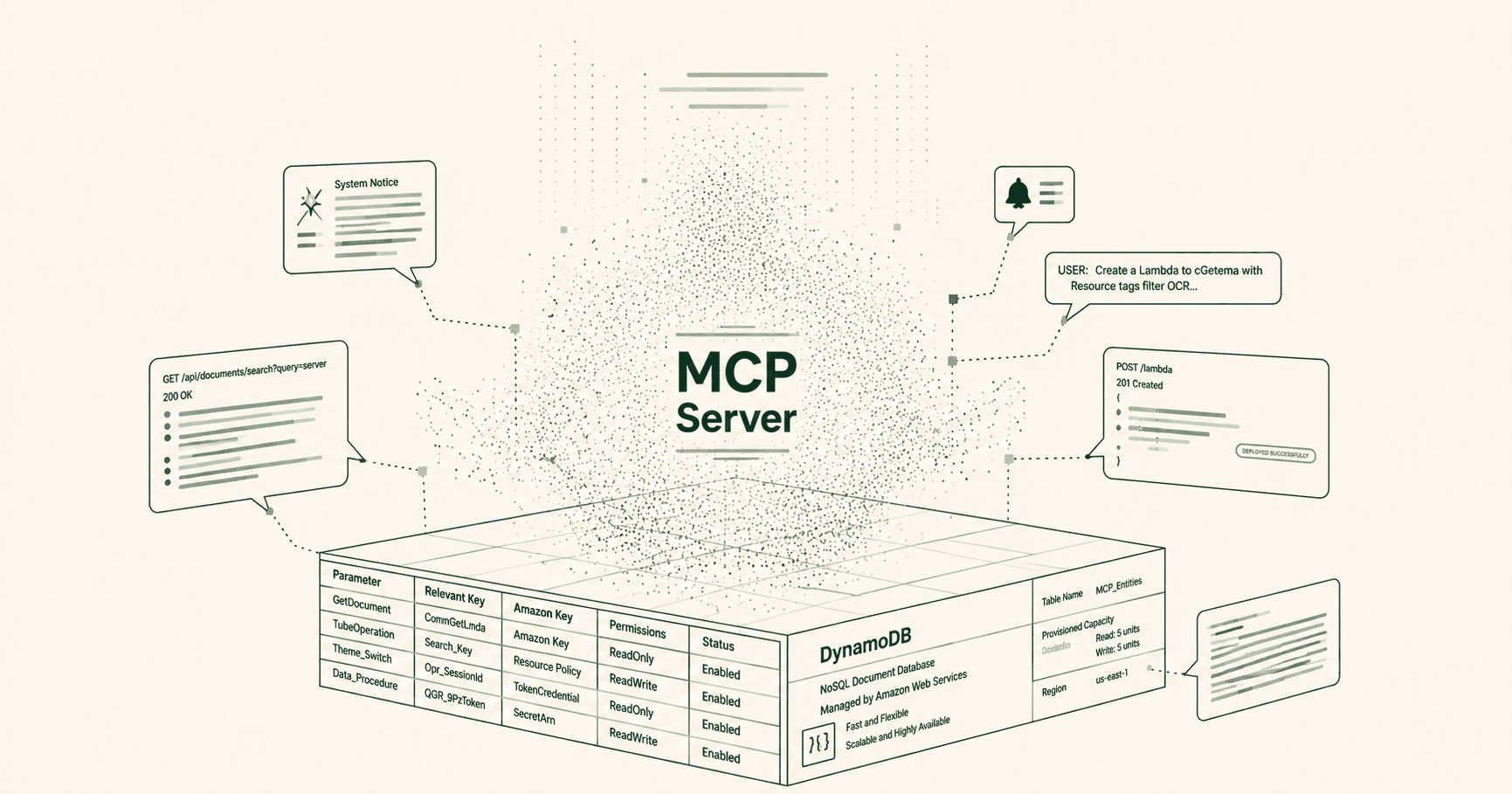
Data modelling for DynamoDB is often a complicated task due to a fundamental shift in design philosophy compared to traditional databases. You need to approach things using ‘access pattern driven design’, which means that you need to know all of your application’s query patterns upfront and create the design based on them. This of course is the reverse of the traditional database design and often quite complex (although it can also be a lot of fun). It is also time consuming when using a tool like NoSQL Workbench for DynamoDB where you need to manually test different database models and how those would work with your access patterns.
Amazon DynamoDB MCP Server can really help in this process. You can start working through the schema using the MCP server or alternatively you could use it as a learning tool by making your own design first and then seeing whether the tool would have done the same design. The feedback you get is quite detailed, so it will really help to understand why the tool has taken certain decisions.
There are several ways to run the MCP server using agentic tools. I used it with AWS Q CLI and the installation is straightforward. The configuration is simply added to the settings files of the AWS Q, and after that it is able to use the tool whenever you open a new AWS Q chat in the terminal:


The process starts by describing the type of application you are building and the business context. The tool will ask you questions, and based on your answer,s it will keep completing the requirements on the list that is shown in the terminal, as well as the complex requirements in the two files it is saving in your current folder: dynamodb_requirements.md and dynamodb_data_model.md

After having an overview of the type of application we are building and the basic requirements, it is time to list the exact access patterns. The tool does this by asking questions about the volume and exact functionality that is required:

The tool will work through adding access patterns, and it will also suggest you ones that you might have forgotten, such as return, getting low stock alerts, or admin functions like user management in the context of the inventory management application.
After collecting all of the access patterns, the tool is ready to finalise the data model design. A detailed description is saved in the markdown document, and it will also give you a summary on the terminal. It will also explain the key design decisions it has taken:

One of the best things is that you are also able to ask it questions about the design. Below is an example of a question, and the answer is quite detailed — only parts of it are shown below

The example answer regarding simple table design also covered the problem a single-table design would create in this scenario, such as sales reports needing to use FilterExpression and what kind of requirements might have made the tool choose a single-table design, such as if brand changes were affecting product displays immediately. You can ask more in-depth questions about any of the aspects and you would get more detailed explanation with examples of situations where for example a single table design would be suitable.
After the initial database design, you are able to continue the discussion and make changes. After I had finalised the initial database modelling, I asked the tool to add modelling for an OCR (Optical Character Recognition) process with a ‘human in the loop’ implementation. We had a short back-and-forth conversation about the functionality that I wanted to achieve by having a system that will send label images to AWS Textract, after which a Lambda function will check against the database whether the brand and model name exists or whether it is something that has already been misread and corrected before. Otherwise we would need to find the closest match (using for example string similarity algorithm as it is not something that DynamoDB supports natively) which is then sent to the frontend for the human to check the correctness. Essentially this would be a system that will improve its correctness over time.
When the tool was aware of the schema and how the process would work, it was able to explain the steps that would be taken as part of the workflow:

Apart from helping with the database modelling, the tool can also help you implement it and it can also help you manage the database (in the context of CRUD actions and schema-level interactions), as long as you have your AWS credentials set up. I personally feel the database modelling is the greatest advantage that it offers as that is usually the most demanding aspect.
After I had finalised the database design, I did also take advantage of the tool’s awareness of the schema and made it create some of the queries for me using my preferred SDK. I was then able to simply copy and paste the queries directly into my code. In summary, I found the tool very useful and will definitely use it to get started with my next DynamoDB project.
It is worth noting, that the tool’s recommendations are advisory and a human review, load testing and validating assumptions remains crucial. It could be that the model will for example propose GSIs that looks optimal for access patterns but under high write loads could create hot partitions. LLM-driven explanations can also occasionally state implicit assumptions (e.g. expected query frequencies) and you need to verify that these actually match your real usage.