I learned systems thinking without knowing it
Backend-focused full-stack developer with AWS cloud knowledge. AWS Community Builder (Serverless category). Passionate about knowledge sharing.
It is interesting to think how our understanding of a topic is influenced by our earlier, seemingly completely unrelated experiences. I didn't initially learn systems thinking from cloud architecture, but I recognised it as I had already seen the same failure models while working for a decade in operations using enterprise systems. Of course at the time none of this felt like systems thinking. It just felt like learning to do my job - with a genuine curiosity about how the system actually worked. It was only years later, working with AWS serverless architecture, that I realised I had already internalised the mental models — I just hadn't had the vocabulary for them yet.
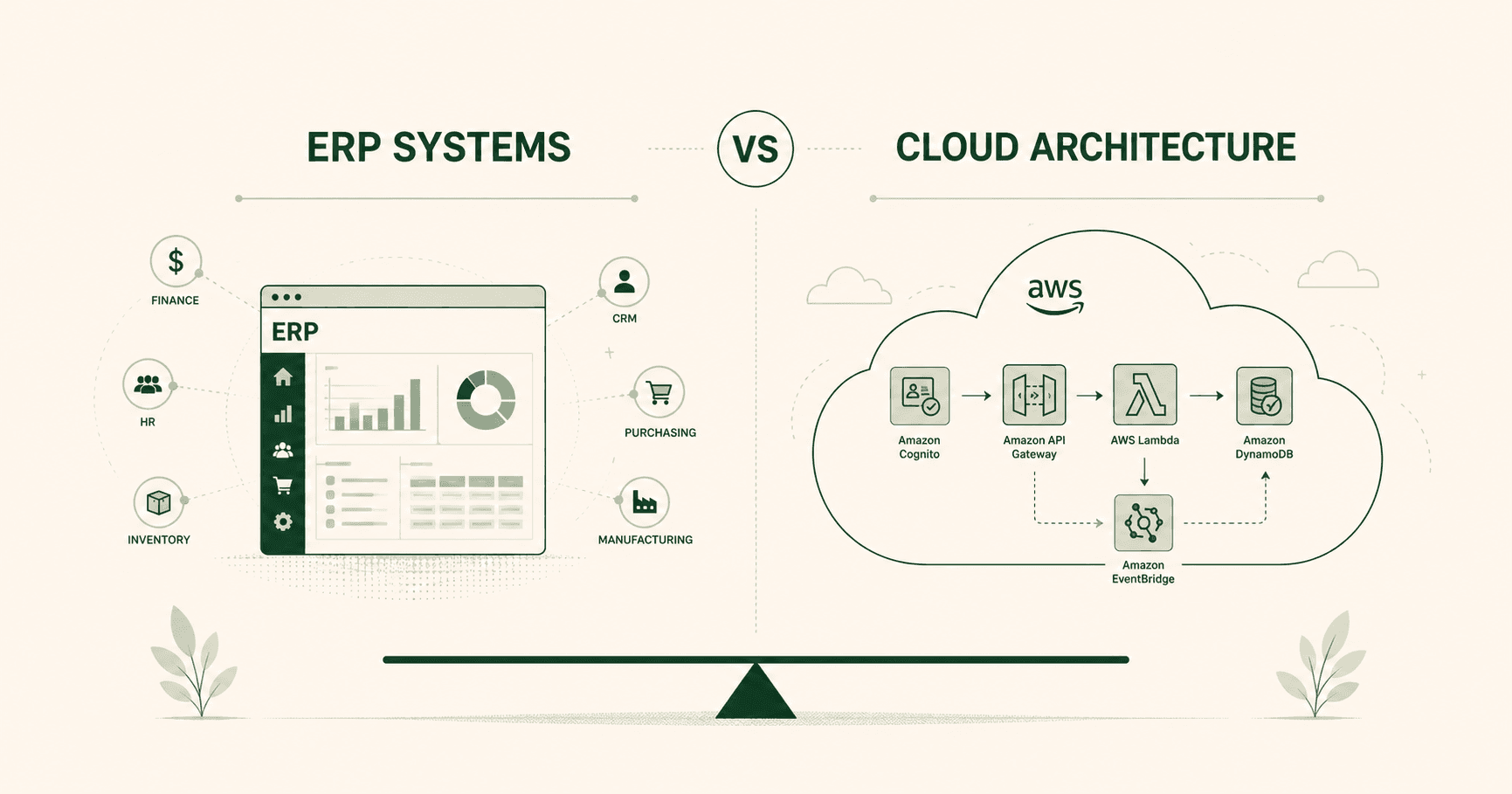
User's view of the ERP system
A typical ERP (Enterprise Resource Planning) system is an incredibly complex business management software that will handle many separate functionalities such as HR, finance, warehouse or order management. Each user in these specific departments would see only their part of the software, which would occasionally fail when communicating with other departments - think of an order management system getting delivery dates from the warehouse. They might get a date that doesn't make sense, contact the warehouse and the warehouse would confirm that they see a different date - conclusion being that there is something wrong with the 'connection' between the two systems.
Apart from failures there are also other scenarios where the ERP systems might cause confusion to the users, such as when the requirements of one department force a user on another department to do some actions that don't fully make sense to their own workflow. For example - order management not able to mark an order as 'fully completed' even though the order has been shipped and delivered with the exact customer requirements - as that would cause the status at the finance department to move to 'finalised' (and recognised revenue) too soon. This could be the case for example in the capital equipment industry - it is not enough to simply deliver a large equipment but it might actually have to be installed or tested before we can 'close the deal' and formally recognise revenue. So the finance department wouldn't want to see this order in their books until they all requirements have been fulfilled, but that might not as such make sense for order management, without having an extended understanding of the connection between the two.
One department as part of a larger ecosystem
In this article I'm mainly looking at simple connections around order management specifically. As ERP systems are so complex, there is obviously a lot more that could be said, but the most common daily connections can be described in the below diagram:

Order management would have constant interactions with the customers. Orders might arrive electronically or manually. Electronically there would probably be some kind of third party tool that might cause things to break - some information could be missing or arrive in the wrong format. There would need to be communication towards the customer in the form of order confirmation - which might be delivered containing wrong or missing information for various reason.
The other main partner is the warehouse. When order management places an order, they might want to reserve a certain serial or lot number, or a delivery date, based on customer requirements. This information might go missing somewhere along the way. In return, the warehouse should confirm the scheduled delivery date and the shipment date - which might then flow to the order management side incorrectly.
The interactions with finance were already mentioned above - there could be the revenue recognition discrepancies for large equipment or commonly also issues around invoices and credit notes.
To summarise, the issues could be caused by layered business logic causing different departments to see different things at certain points of time, batch processing running at certain times or even timezone issues. But that is not the point of this article - we are simply looking at the ERP systems from the user's perspective, without the deep technical expertise to understand how these type of systems operate under the hood.
When to debug?
From an inexperienced user's viewpoint any discrepancy in their system is a mystery and they would opt for either blindly trusting the data or not knowing when to trust it at all. For example - they might take any possible delivery date as an absolute source of truth or manually check with the warehouse every time before communicating anything to the customer. Either approach would be unproductive in the long run. Similarly an inexperienced user might read the system strictly from real-life perspective without thinking about the technicalities - for example a customer calls and complains that they have received two invoices and the user would simply create a credit note to make the customer happy. This would initially work from their perspective but cause a waterfall effect that would create issues for finance at the very least.
An experienced user, however, would almost learn to read the system without having any access to the logs. For example - they would see a scheduled delivery date for a certain product one week from now and would know that this kind of date is unlikely to be realistic due to usual longer delivery times. Or they would see an unusual date and note that this date has for some reason been entered as a 'dummy date' for similar items before. They would know when to contact a human to verify whether what they see is correct or whether there is an error that needs correcting. They would also not create data (for example those credit notes) simply to fix an issue in front of them, without thinking the way the data flows and causes related issues across other departments.
In a nutshell, that is something that you only learn through experience. You immediately see where something looks 'wrong' and know where to start debugging - and you would know where you are able to manually fix things without causing problems. You identify that there are certain 'connections' that can for one reason or another just be 'blocked' or somehow 'corrupted' causing the data not to flow as it should. When things work, they work smoothly. And when they don't, you need to know where to look under the hood. Not so different from the cloud, a cloud engineer might say.
Collection of event-driven workflows
When we think about the ERP system, it can be seen as a collection of different business processes. You would have order management that needs to do certain things - verify the customer order, make sure customer's preferences for delivery dates are recorded and confirm whether an installation of the equipment is needed etc. Their part of the system needs to be able to fulfil these requirements. Similarly a warehouse has their own real word constrains that they need to take into consideration - how long does it take to pick up an order, how many can we do in a day, how do we verify what is shipping and when. They are both their own distributed systems, both doing their own 'thing' but both depending on each other. If they don't submit or get the correct data, things break. Service boundaries separate them and that is where the data exchange happens.
You could also think about the order lifecycle as a collection of event-driven workflows. Some of the main events would be the following:
receiving an order kick-starts the life-cycle. The order is entered into the system based on real life constraints and it will then flow to the other relevant departments such as the warehouse and finance.
receiving a scheduled delivery date from the warehouse would initiate several workflows towards the customer, order management and possibly an installation team, letting them know the date so that they can make real-life plans accordingly.
receiving a delivery confirmation would initiate several workflows to notify order management (to mark the case as 'closed'), finance (in case they are ready to recognise revenue upon delivery) and perhaps sales to make them aware of their confirmed sales statistics.
In an ideal scenario, when these events work and cascade automatically, things go smoothly and all real-life events can be planned accordingly. However, the more automation there is, the more you need humans that understand what happens across service boundaries and can monitor when things are not working.
Moving on to the cloud
Distributed systems, event-driven workflows, thinking about service boundaries - all the of the themes described above are also highly relevant to cloud engineering. Let's think especially about AWS serverless as an example. You are forced to think explicitly about boundaries. API Gateway wants to do its thing - it gets a request from the frontend (or elsewhere), checks what rules it needs to follow (maybe it needs an authorisation or an API key), where it should forward the request to (let's say a Lambda function in this case), whether it should somehow modify the request or simply act as proxy - and based on all these considerations it will make a decision and either block the request or forward it.
Then you have the Lambda function doing its own thing - receiving something from the API Gateway and following function logic in deciding what to do with it. If the request is not the type of data it was expecting or something is missing in the configuration, it would simply return an error.
If the request goes through API Gateway and Lambda function is able to process it, it might need to perform a database (for example DynamoDB) query. Again you have the DynamoDB doing its thing. If all the configurations and permissions and data models are correct, it would return or write the data and if not, it would return an error. Each part doing their thing in their own silos. Everything working smoothly until it doesn't.
So you would have all these service boundaries where things can break. Some kind of small mismatch - a missing permission or a configuration error - could cause the data not to flow correctly and you would end up having two services with different realities - one would look like everything is working as expected while the other would get a response or data that it was not expecting. And somewhere in the chain you would have a human who is looking at the data that doesn't seem to make sense.
With experience, you would know what is most likely to break and where the usual issues are. Even when you have access to the logs, things are not always obvious and you have to almost have an intuition where to look for the root causes. A notorious example could be when you are trying to make a request to an API Gateway resource and get the error {"message": "Missing Authentication Token"}. This could look extremely confusing if you have never seen that before and you might start checking all kinds of things from IAM permissions to frontend authorisation tokens. But an experienced user would just note that they have forgotten again to re-deploy the API Gateway and check whether doing that would clear the error.
Common Factor
In both systems, when different departments/services are communicating with each other and things break, there is usually always a human somewhere along the line who needs to know where to look. That human will either correct the error or cause even more chaos by attempting some kind of corrections that completely mess things up. Any local optimisations can create global problems and all actions have downstream effects.
Someone might of course say that all these 'human in the loop' issues are soon history when the AI agents are able to manage these sort of service boundaries a lot more efficiently. But the issue remains the same - even for AI agents the results are only as good as the context they have been given. Just as a human operating these systems would need to understand their unique business context and the way certain departments interact with each other, this context would have to be given to AI as well. Otherwise it would be working based on assumptions that could be misleading. So the context problem doesn't go away, it just transfers.
For me personally, the biggest common factor is the mindset. You have to accept that each individual service is working it its own silo and needs to serve its purpose. And each participant has only partial information. The warehouse and order management both believe they are correct and similarly the API Gateway and Lambda both believe they are correct - somewhere in between there needs to be a human who can interpret between the two.
At the end of the day each one is just a wheel of a larger system, unable to achieve anything on its own and you have to accept your ignorance of perhaps not knowing all of the wheels in depth. The biggest mistake you can make, is to think that your micro service or department is the source of truth and the only thing that matters. It is all just part of a system.