Personalising LLM Output with DynamoDB and Deterministic Filters
Backend-focused full-stack developer with AWS cloud knowledge. AWS Community Builder (Serverless category). Passionate about knowledge sharing.
When I started building an application that extracts key concepts and vocabulary from a text, I thought I could handle personalisation through the prompt alone. It turned out that getting reliable results from the LLM was not that straightforward and I ended up implementing further steps with rule-based deterministic filtering in code after the LLM response.
I'm walking through the basic functionality of the application below as well as covering the main obstacles I came across and the way I navigated them. For this project the AI model that I was using was Amazon Nova. In a production context you would do a proper evaluation across models, however here I was working within the constraints of a hackathon build and used Nova on available AWS credits.
The Application
This project contains a full-stack application with Flutter web frontend and AWS serverless backend (API Gateway, Lambda, DynamoDB, Bedrock). The app creates sessions for the user by triggering a backend Lambda function which orchestrates the Quran content API fetch and the Amazon Bedrock request. This is the core structure of the prompt used for Bedrock (abbreviated):
You are a Quran study assistant. Your sole source of
information is the passage provided below — do not draw on
outside knowledge.
# [passage and user context variables injected here]
# [summary task, validation rules, and JSON output schema removed]
KEYWORD TASK:
Extract exactly 30 keywords directly from the passage.
STEP 1 — KEYWORD SELECTION:
Calibrate the word list strictly to ARABIC LEVEL...
STEP 2 — RANK by semantic centrality: ask yourself "if the
reader understood only the first 5 words on this list, how much
of this passage's core message would they grasp?"..
STEP 3 — LABEL each keyword:- "focus" → essential for
understanding this passage's core message - "advanced" →
morphologically complex, rare, or semantically nuanced
STEP 4 — VOCALIZATION: Every "arabic" value MUST include full
harakāt (tashkīl)...
STEP 5 - For each word, also return its base form (lemma/root).
...
The prompt is requesting the LLM to create a short summary and a list of keywords from that text. This is simple, exactly what LLMs are good at - until you try to make the output personalised for the user as you obviously would like the keywords to be. An advanced user would not benefit from a similar keyword list as a beginner, and no user would want to see the same keywords repeated across sessions - if they learn a certain word, they would want the subsequent session to teach them new keywords.
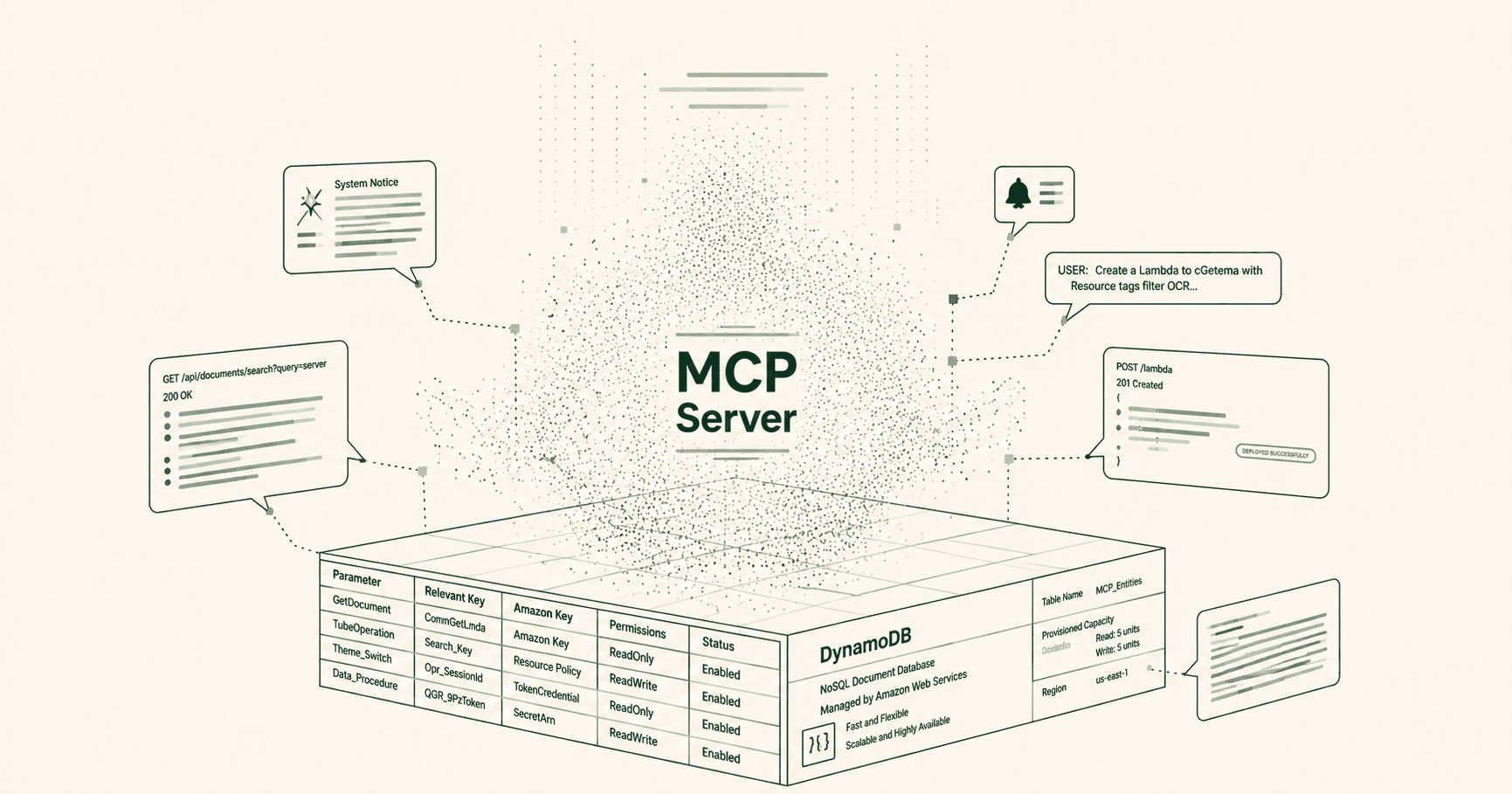
The initial idea was to provide all the necessary information as part of the prompt and let the LLM do the heavy lifting in terms of creating a finalised list of keywords, however getting this to work in a reliable manner turned out to be problematic. For this reason, I ended up implementing several layers of deterministic filtering, which are summarised in this diagram and described below in more detail:

Deterministic filtering approach
The user is able to personalise their sessions on two levels: by selecting their Arabic level (beginner/intermediate/advanced) and by flagging words that they already know while completing the sessions. I had to make sure that any keyword list creation takes these two levels into consideration.
Filtering known words
As the application is using DynamoDB as a database to store user data and sessions, the logical extension of this was to store also the familiar keywords there as they flag them when completing sessions. This would enable the creation of personalised experience that would let each user build their knowledge over time.
The initial idea was to simply submit these keywords to the LLM as part of the prompt and ask it to exclude these words from the keyword list that it creates. As an idea this seemed simple enough 'the user already knows xyz, please don't include xyz in the keyword list you create' - however in practice it didn't seem that the LLM was able to reliably follow this instruction. It was simply often ignoring it completely.
For this reason, in order to have a better control of it, this filtering had to be handled programmatically. So after the list of keywords was returned from the LLM, a list of user's known keywords would be fetched from the database and the known keywords would then be excluded from the list. But before this, there was also a further step that had to be implemented.
Level-based filtering
Apart from manually flagging words as 'already known', the user also selects their Arabic level in the app settings. This level is fetched from the database every time we are asking the LLM to create material for them. I tried three approaches in sequence: prompt-only, hybrid LLM+data, and finally full deterministic filtering
The initial prompt contained clear instructions to personalise the keywords based on the user's Arabic level, however in this format it returned quite varied results:
Calibrate the word list strictly to ARABIC LEVEL. A beginner needs the building blocks of the passage — include common and high-frequency Quranic vocabulary. An intermediate reader already knows everyday Quranic nouns, verbs, and prepositions — skip these unless they carry an unusual meaning
here. An advanced reader knows the Quranic lexicon broadly — only surface words that are rare, morphologically complex, or semantically nuanced in this specific passage. When in doubt, ask: would a reader at this level already know this word from general Quran exposure? If yes, leave it out.
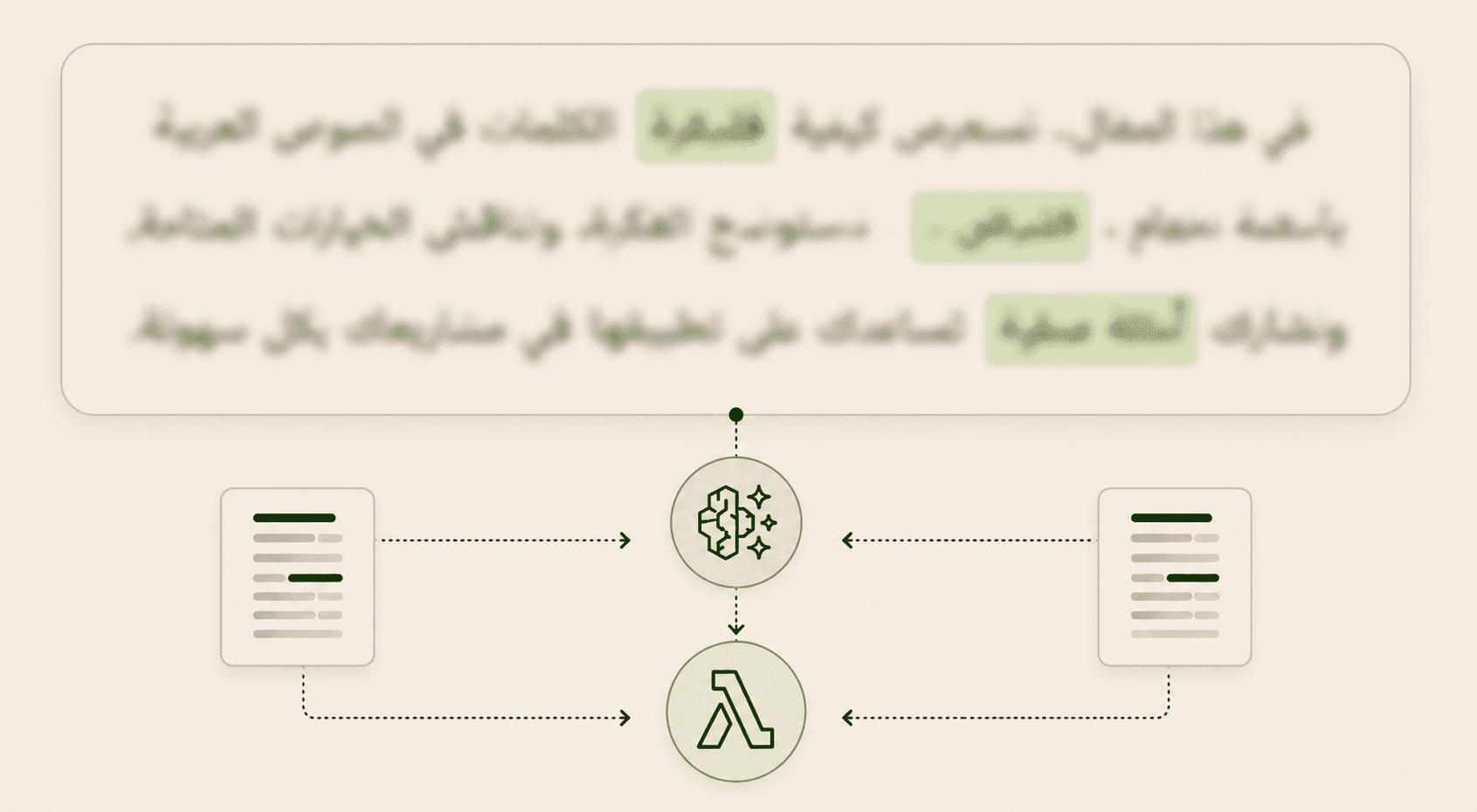
As the response to this prompt was not satisfactory, I set up JSON files with typical known words for intermediate and advanced readers - stored at the backend. I sent these files to the LLM and requested it to modify the response based on user's level and relevant words on the files. As this approach wasn't accurate enough either, the most choice was to do this programmatically instead. So the LLM would return a word list to the Lambda function which would then programmatically compare this list to the JSON file and filter out the words that were found in the file - a similar approach to that we already did above for the 'known words' in DynamoDB.
In order to get this work, there was a further step that had to be implemented. Due to the nature of the Arabic language, words can exist in several different forms while the words on the list are only in their root word format. So I needed some help here from the LLM so that I would also be comparing the words in the exact same format:
STEP 5 - For each word, also return its base form (lemma/root).
Return JSON like:
[
{ "word": "كفروا", "lemma": "كفر" },
{ "word": "قالوا", "lemma": "قال" }
]
For a production application, a more thorough word list could be used containing all different word formats which would remove this responsibility from the LLM entirely and make the system more reliable. However, in initial testing the LLM seemed to reliably return the root words as requested.
Final flow
The final flow for the session creation now looks like the following:
The user selects a chapter or a page range and rates their familiarity with the content (new, somewhat familiar, or well known)
The backend retrieves the user's Arabic level (beginner, intermediate, or advanced) from their stored preferences
The text is fetched from the Quran Foundation Content API
The passage, familiarity rating, and Arabic level are sent to Amazon Bedrock (Nova Lite), which generates a 3-bullet overview and a ranked list of key vocabulary
The keyword list is then filtered in two passes:
Level-based filtering — removes common or high-frequency Quranic words based on the user's Arabic level. Beginners see all words; intermediate users skip common ones; advanced users skip both common and high-frequency words.
User-specific filtering — removes any keywords the user has already marked as "known" in previous sessions, so each session only surfaces new vocabulary.
The final overview and up to 20 filtered keywords are returned to the frontend as preparation material (the prompt requests the LLM to return 30 keywords to give some buffer for filtering)
It is worth mentioning that this article mainly concentrates on the keywords, although the application also creates summaries. For those I'm currently relying on the user's level in the prompt alone (whether they are completely new to the chapter/pages or are already familiar with them). The results are somewhat inconsistent, and my instinct for further improving this would be few-shot prompting - providing the LLM with concrete examples of summaries at different familiarity levels so that it has a clearer target to aim for.
I started this project thinking personalisation was a prompting problem, but the best results were achieved by letting the prompt handle the intelligence and the Lambda function handle the precision.